AI Tooling
Policy-as-Code for AI Agents: Stop Hardcoding Authorization in Prompts
Enterprise agents don’t fail because they can’t call tools — they fail because nobody can prove the calls were allowed. Here’s the reference architecture for decoupled, auditable authorization using policy engines (Cedar/Verified Permissions).
Most enterprise “agent” demos skip the hard part.
They show an LLM calling tools.
They don’t show who was allowed to call which tool, on which resource, under which context — and how you’ll audit that decision a month later when something goes wrong.
In 2026, the fastest path to “agent-in-prod” incidents is still the oldest sin in application security:
Authorization logic scattered across UI code, microservices, and now… prompts.
The fix is the same pattern we’ve used for APIs — but now it must cover agents too:
The architectural shift: treat authorization as a platform capability
Instead of encoding access rules in:
- tool wrappers
- microservice handlers
- prompt instructions (“only do X if the user is Y”)
…move them into a central authorization service driven by policy-as-code.
Authorization decision flow:
User intent → Agent runtime
│
▼
Tool router (enforcement point)
│
▼
AuthZ engine (Cedar / Verified Permissions)
Inputs: principal, action, resource, context
│
┌──────┴──────┐
▼ ▼
ALLOW DENY
│ │
▼ ▼
Tool execution Audit log + error
│
▼
Audit log (decision + policy version)This does two things that matter for real enterprises:
- Consistency: the same rule applies whether the action is initiated by a human UI, an API client, or an agent.
- Auditability: every decision can be logged with inputs, policy version, and decision rationale.
Why agents make authorization harder (and more important)
Agents change the failure modes:
1) Intent ≠ action
A user says: “Help me close this deal.”
An agent might:
- read CRM records
- pull attachments from Drive
- generate an email
- create discounts
- update opportunity stages
That’s multiple privileged operations across systems. You need fine-grained decisions per tool call, not a single “user is logged in” check.
2) Context explosion
With agents, context becomes part of authorization:
- tenant and business unit
- role + delegated authority
- customer/account ownership
- data classification (PII, finance)
- risk signals (device, location, anomaly score)
If your rules aren’t expressed and reviewed as first-class artefacts, you will ship inconsistent controls.
3) The “seat-based” guardrail disappears
In classic SaaS, the UI naturally constrained what users could do.
With agents, the UI is optional — tool calls can go straight to APIs.
So your real security boundary becomes your tool router + authz engine, not your web app.
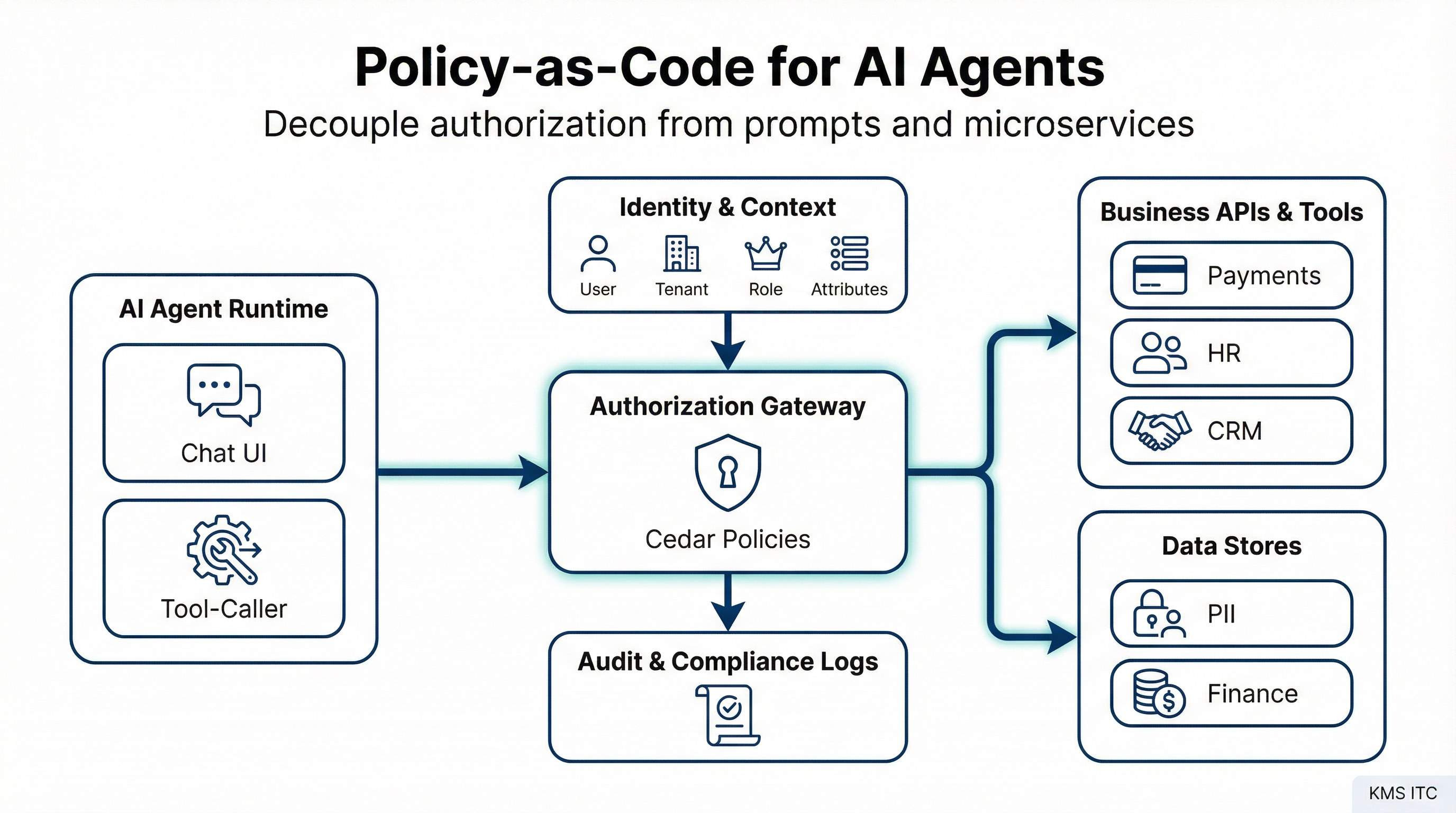
Reference architecture: policy-as-code authZ for agent + APIs
The cleanest way to scale this is to standardise an “authorization control plane”:
Authorization control plane — components:
| Component | Purpose | Non-negotiable |
|---|---|---|
| Identity + context ingestion | OIDC/JWT principal + tenant, org, entitlements, risk signals | Context must be explicit and typed |
| AuthZ engine (Cedar / Verified Permissions) | Evaluates: can P perform A on R given C? | Deny by default |
| Policy store + CI/CD | Versioned, peer-reviewed, tested policies | Rollback must be faster than your incident bridge |
| Tool / API gateway | Single enforcement point for all agent tool calls | No “internal tools” bypass, ever |
| Audit trail | Principal, action, resource, context, decision, policy version | Must answer “why was this allowed?” |
Key components (and the non-negotiables)
1) Identity + context ingestion
- OIDC/JWT gives you the principal
- a context service enriches with tenant, org hierarchy, entitlements, risk signals
Non-negotiable: context must be explicit and typed; no “mystery meat” headers.
2) AuthZ engine (policy evaluation) A policy engine (for example, Cedar policies evaluated by Amazon Verified Permissions) answers:
- Can principal P perform action A on resource R given context C?
Non-negotiable: make “deny by default” the baseline.
3) Policy store with CI/CD Treat policies like code:
- versioned
- peer-reviewed
- tested (unit tests for high-risk rules)
- deployed through environments
Non-negotiable: you need a rollback story that’s faster than your incident bridge.
4) Tool/API gateway enforcing decisions All agent tool calls must go through a common enforcement point:
- a tool router for LLM function calls
- an API gateway / service mesh for service-to-service calls
Non-negotiable: don’t let “internal tools” bypass authz “temporarily”. That temporary thing becomes permanent.
5) Audit trail designed for investigations Log:
- principal, tenant, action, resource
- context snapshot (or hash + reference)
- decision + reason
- policy version
Non-negotiable: if you can’t answer “why was this allowed?” you don’t have governance — you have vibes.
Tradeoffs (because nothing is free)
Tradeoff 1: latency vs safety
Centralised decisions add an extra hop.
Mitigations:
- policy caching with short TTL
- precomputing entitlements
- co-locating authz service with gateway
Rule of thumb: sub-10ms is achievable; if you’re adding 100ms you’ve built a data-lookup engine, not an authz engine.
Tradeoff 2: policy sprawl
As you add tenants, actions, and resources, policy volume grows.
Mitigations:
- schema-driven modelling (actions/resources are enumerated)
- templates for common patterns (owner-based access, ABAC)
- “policy product ownership” (platform team + security co-ownership)
Tradeoff 3: teams will fight about who owns it
This is normal.
A workable operating model:
- Security owns guardrails + review for high-risk policies
- Platform engineering owns the authz service + tooling
- Product teams own domain policies (within guardrails)
What to do next (practical checklist)
If you’re building an enterprise agent platform, start here:
- Inventory tools your agent can call (APIs, DB queries, workflows)
- Define a minimal policy schema:
principal,action,resource,context - Build a single enforcement point (tool router/gateway) before you add more tools
- Add a “high-risk actions” class (payments, user admin, exports) and require stricter context
- Ship the audit log format now — don’t wait for incident #1
The KMS ITC take
Agents don’t remove the need for governance — they move it left.
The winners will be the organisations that can say:
“Yes, we let agents operate — and we can prove every tool call was authorised, least-privilege, and reviewable.”
Sources
- AWS Architecture Blog: fine-grained API authorization with Verified Permissions
- Amazon Verified Permissions overview
- Cedar policy language
If you want, reply with your current agent/tool stack (even a rough list). I’ll map it to a least-privilege tool catalog + policy schema you can implement in 1–2 sprints.