AI Architecture
Amazon Bedrock in the enterprise landing zone: a control-plane pattern for AI access, governance, and cost
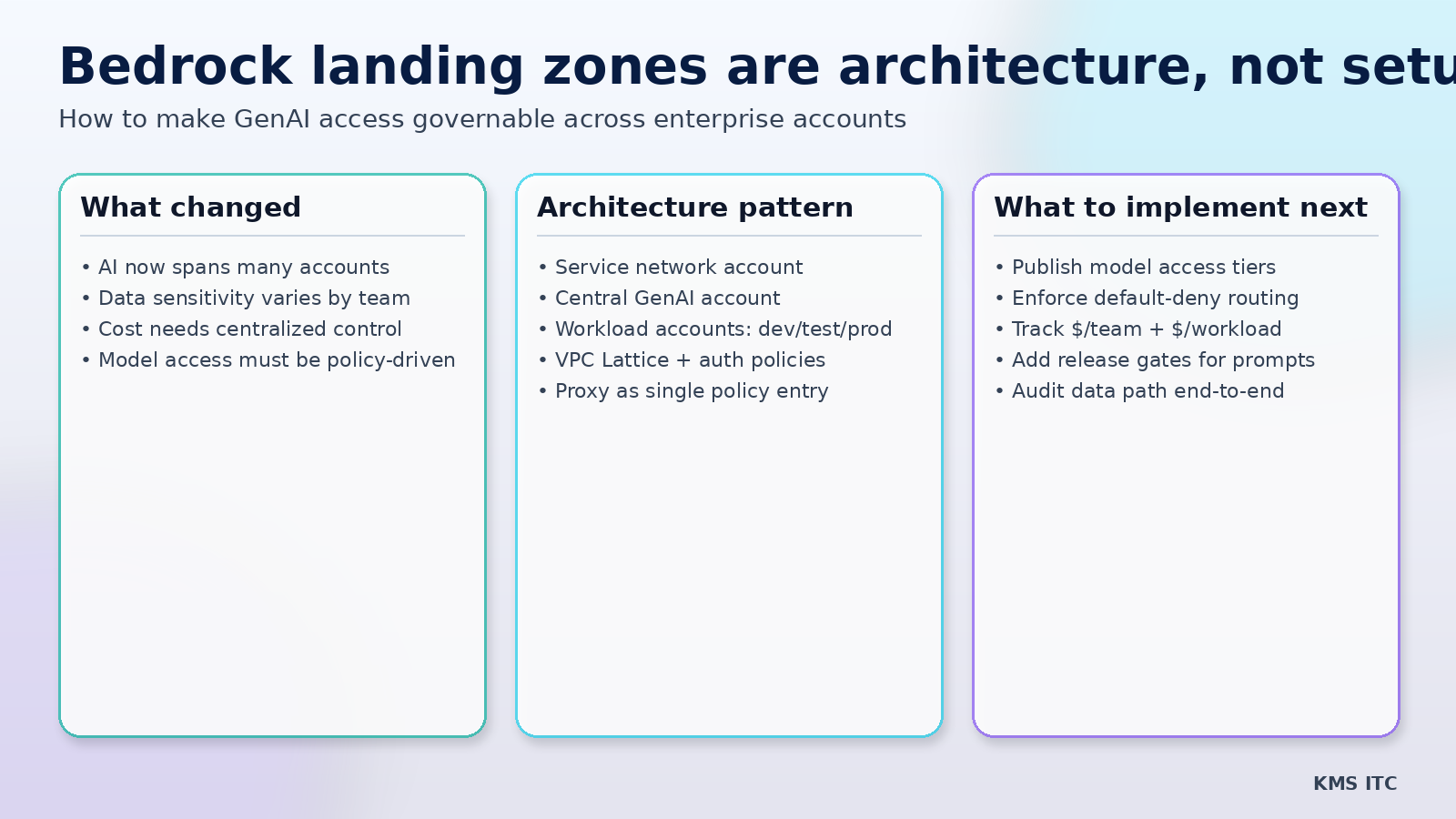
The critical shift is architectural: centralize GenAI capability, decentralize workload ownership. Here’s how the Bedrock landing-zone baseline maps to enterprise control planes and what to standardize next.
Enterprise GenAI programs are hitting a familiar scaling point:
- one team can ship quickly,
- ten teams create access sprawl,
- and suddenly security, cost, and model governance become the bottleneck.
The latest AWS architecture guidance around Amazon Bedrock in a landing zone is useful not because it adds one more reference diagram, but because it reframes the operating model:
Treat GenAI access as a platform control plane, not an app-level integration detail.
1) The capability jump (what matters beyond the feature list)
The architecture pattern introduces a practical three-layer split:
- Service network account for centralized network and auth policy
- Generative AI account for Bedrock capabilities and model governance
- Workload accounts (dev/test/prod) consuming controlled AI services
This matters because it decouples two concerns that are often mixed together:
- AI capability lifecycle (model onboarding, policy, cost controls)
- Product delivery lifecycle (team-specific release cadence and accountability)
If those lifecycles are fused, either governance blocks delivery or delivery bypasses governance.
2) Architecture implication: establish an AI access control plane
A strong enterprise pattern is to create a shared AI access plane with clear boundaries:
Enterprise Bedrock landing-zone — account structure:
┌─────────────────────────────────────────────────────────┐
│ Service Network Account │
│ (VPC Lattice fabric, central connectivity, auth policy)│
└──────────────────────┬──────────────────────────────────┘
│
┌────────────▼────────────┐
│ Generative AI Account │
│ (Bedrock models, KBs, │
│ guardrails, proxy) │
└────────────┬────────────┘
│ default-deny auth
┌────────────┼────────────┐
▼ ▼ ▼
Dev Acct Test Acct Prod Acct
(workloads) (workloads) (workloads)| Layer | Component | Responsibility |
|---|---|---|
| Network fabric | VPC Lattice | Central connectivity and baseline policy |
| AI capability | Bedrock proxy | Single entry path for model invocation and guardrails |
| Policy | Default-deny auth | Allowlist approved workloads, actions, model classes |
| Isolation | Separate workload accounts | Dev/test/prod each consume shared capability independently |
Core design moves
- Use VPC Lattice as the organization-wide service network fabric
- central service network account owns connectivity and baseline policy
- Expose Bedrock via a policy-enforcing proxy layer
- single entry path for model invocation, KB access, and guardrails
- Apply default-deny auth at service-network and service level
- allow only approved workloads, actions, and model classes
- Keep workload isolation intact
- dev/test/prod accounts stay separate while consuming shared AI capability
This gives architecture teams a control point for both risk posture and economics.
3) Tradeoffs you need to design for early
Tradeoff A: centralization can become a platform bottleneck
A single proxy and policy plane can improve control but slow teams down if onboarding is manual.
What works:
- publish self-service templates for common workload classes
- define model access tiers (e.g., baseline, advanced, restricted)
- automate approval paths for low-risk use cases
Tradeoff B: network control is not enough for governance
Even with private connectivity, governance still fails without explicit policy semantics.
Minimum semantic policy set:
- who can call which model families
- which data classes can flow to which endpoints
- spend guardrails by team/workload/environment
- required trace/audit metadata per request
Tradeoff C: cost visibility can be too coarse
Centralized AI accounts often report spend in aggregate, hiding workload-level efficiency problems.
Fix:
- require workload identity tagging in request path
- track $/task, not just monthly account spend
- run FinOps reviews by workload archetype (assistants, extraction, generation, agents)
4) What to standardize in enterprise operating models
(1) A model access catalogue
Define approved model classes with:
- intended use cases
- data-handling constraints
- latency and cost envelopes
- escalation path for exceptions
(2) Reusable AI connectivity patterns
Ship a reference blueprint that every team can reuse:
- service network association
- proxy contract
- auth policy skeleton
- observability and audit defaults
(3) Release gates for prompt and routing changes
Treat prompt/routing updates as production changes:
- baseline vs candidate evaluations
- safety and quality checks
- rollout policy (canary + rollback)
(4) Platform SLOs for the AI control plane itself
Track platform health like any tier-0 dependency:
- policy decision latency
- invocation success rate
- p95 end-to-end latency
- unit economics trends
5) A practical “start this week” implementation plan
- Stand up one central AI account with explicit ownership.
- Route one production workload through a single policy proxy path.
- Enforce default-deny and allowlist by workload identity.
- Add request-level tags for workload and environment.
- Review weekly: policy exceptions, latency regressions, and $/task drift.
The immediate goal is not maximum centralization.
It is controlled decentralization: teams move fast, but on a shared, auditable, and economically visible AI foundation.
Sources
- AWS Architecture Blog: Bedrock baseline architecture in a landing zone
- Amazon VPC Lattice auth policies
- Amazon Bedrock overview
If you want a practical AI landing-zone control-plane checklist (policy model, account boundaries, and rollout guardrails), contact KMS ITC and we’ll help you tailor one to your enterprise context.